TensorBoard Profiling
Main Docs: https://www.tensorflow.org/tensorboard/get_started
Existing tutorials:
- Good example of the projector functionality https://zito-relova.medium.com/tensorboard-tutorial-5d482d270f08
- General introduction to the different tools inside tensorboard
TODO TensorFlow Summary Trace API to log autographed functions for visualization in TensorBoard. https://www.tensorflow.org/tensorboard/graphs#graphs_of_tffunctions
Q & A
Q: Do you need to add tf.function to each separate model subclass’s cal function?
A: Nope, “In TensorFlow 2.0, users should refactor their code into smaller functions which are called as needed. In general, it’s not necessary to decorate each of these smaller functions with tf.function; only use tf.function to decorate high-level computations — for example, one step of training, or the forward pass of your model.” -https://blog.tensorflow.org/2019/02/effective-tensorflow-20-best-practices.html
Q: When/how should I be using input_signature arg with tf.function?
Q: What happens when you add nested tf.function calls in a graph?
A: If you are adding a ton of tiny kernels that would have otherwise been fused, it’s not great to do.
https://stackoverflow.com/questions/71713428/effect-of-nested-tf-function-calls-on-computation-graph
Tensorboard Profiling
We don’t care about actually training the network while we are profiling. Rather, we just want to figure out how the network is dispatching ops to the GPU. As long as there are no overflowing gradients or weird things happening, the operations getting dispatched are the same regardless of whether the model is wholly untrained with random weights or freshly fine-tuned.
PartitionedCall - calls stateless tf functions - Typically used in graph mode. - Represents a call to a function that can be partitioned across multiple devices or processed in parallel. - It doesn’t inherently imply that the function is stateless; it just doesn’t explicitly manage state in a way that TensorFlow tracks separately. - Often used for standard function calls, including those involving computations like gradient updates.
StatefulPartitionedCall - calls stateful tf functions - For functions that rely on or modify an internal state during their execution, such as RNNs, optimizers, or any function that updates model weights. - Ensures that state changes (e.g., variable updates) are properly managed and synchronized. - Commonly used in scenarios where the function’s state must be tracked across multiple calls, ensuring consistency and correctness, particularly in distributed or multi-device settings.
In summary, PartitionedCall is used for partitionable function calls in TensorFlow, which may include state changes but doesn’t explicitly track them. StatefulPartitionedCall explicitly manages and tracks state changes across calls.
Tensorboard callback
Example callback
tb_cb = tf.keras.callbacks.TensorBoard(
log_dir='toy-model-xla-tblogs',
histogram_freq=0,
update_freq='epoch',
write_graph=True,
profile_batch=(5, 12)
)
The callback is passed to model.fit():
history = model.fit(x_train, y_train,
epochs=1,
batch_size=64, steps_per_epoch=16,
# callbacks=[tb_cb]
)
General Vibes
We want to keep the batch size at the value we actually want to train at, rather some smaller value. Since we don’t actually care about training the network, there’s other values like steps_per_epoch and number of epochs we can tweak to make profiling faster.
First of all, we only need to train for one epochs to do useful profiling.
To further speed things up, limit the amount of training data per epoch using the steps_per_epoch arg in model.train() function. Now you can select a subset of batches to profile from the limited batches being used in an epoch. For example
effective batch size = batch size * steps_per_update (number of timesteps per batch) total steps = training examples / effective batch size 1 update = 1 step = 1 batch. A batch is a subset of the training dataset used in one step steps_per_epoch « total_steps total_batches_to_profile = last_profile_batch - first_profile_batch steps_per_epoch = total_steps = a few warmup batches + total_batches_to_profile
The profiling information for the different batches should be quite similar, but you can adjust which and how many batches you profile with the profile_batch arg in the Tensorboard callback. The first value in the tuple is the batch to start profiling, and the second value is the batch to stop profiling after.
Once you have limited the number of batches in an epoch. train on a small number of batches and profile on a subset.
make the epochs go faster using the steps_per_epoch arg in model.train(). profile a small range of batches and limit the number of batches per epoch to be slightly larger than the ..It’s best to let the network run for a few batches before profiling in case their is compilation, tracing, caching etc that needs to be done as a one time cost
have a few warmup batches (in other words, don’t profile the first few batches in case there is some caching things that happen just once up front),
For finding out why the Focalnets take so long to train, look at the parts of the IR that are supposed to be parallel, and make sure they are in fact being executed as such and that there are no unexpected “control dependencies” forcing them to be executed in sequence.
Trace Viewer
Understanding Cuda kernel signatures
this conversation might be useful as reference https://chatgpt.com/c/6c7b40ee-d31e-4007-b22c-0d705a9af44c
-
void precomputed_convolve_sgemm<float, 1024, 5, 5, 4, 3, 3, 1, false>(int, int, int, float const*, int, float*, float const*, kernel_conv_params, unsigned long long, int, float, float, int, float const*, float const*, int*)aka the blue kernels -
void implicit_convolve_sgemm<float, float, 1024, 5, 5, 3, 3, 3, 1, false, false, true>(int, int, int, float const*, int, float*, float const*, kernel_conv_params, unsigned long long, int, float, float, int, float const*, float const*, bool, int, int)aka the red kernels -
void wgrad_alg0_engine<float, 128, 5, 5, 3, 3, 3, false, 512>(int, int, int, float const*, int, float*, float const*, kernel_grad_params, unsigned long long, int, float, int, int, int, int)aka the pink kernels
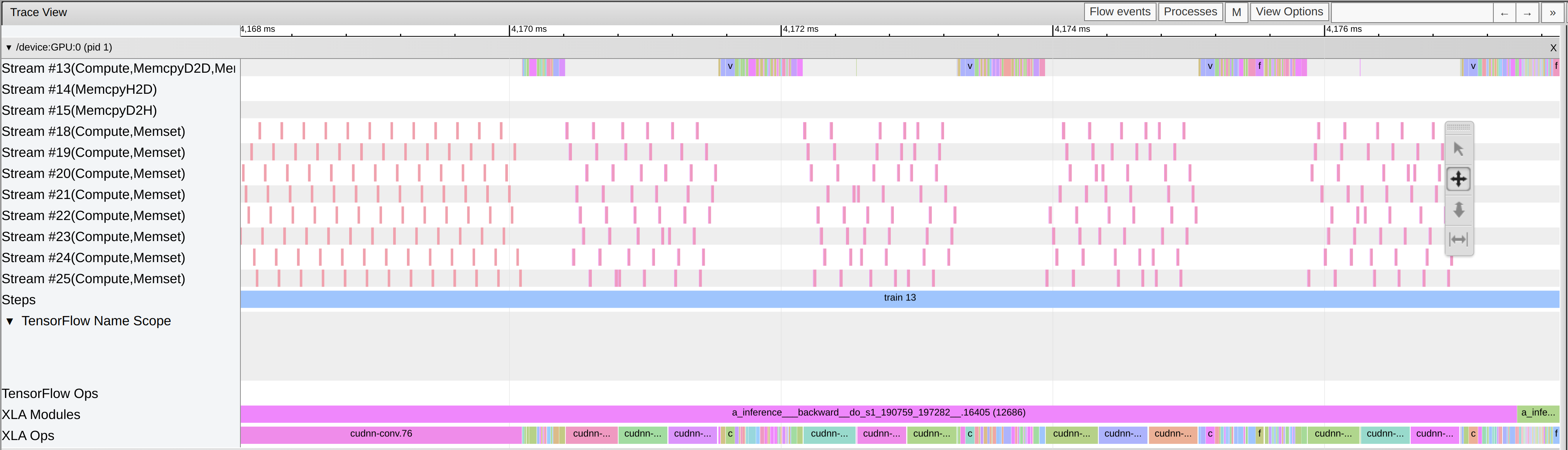
Understanding Streams in the Trace Viewer
MemcpyD2D, MemcpyH2D, MemcpyD2H: These streams indicate memory copy operations:
MemcpyD2D: Device-to-Device memory copy. MemcpyH2D: Host-to-Device memory copy. MemcpyD2H: Device-to-Host memory copy.
Notice that the Focalnet has a bunch of streams, and that the vanilla conv model does not
trace viewer shows the kernel op pairs
Notice that the red wgrad update kernels only happen at the very end up the backward pass for the stage
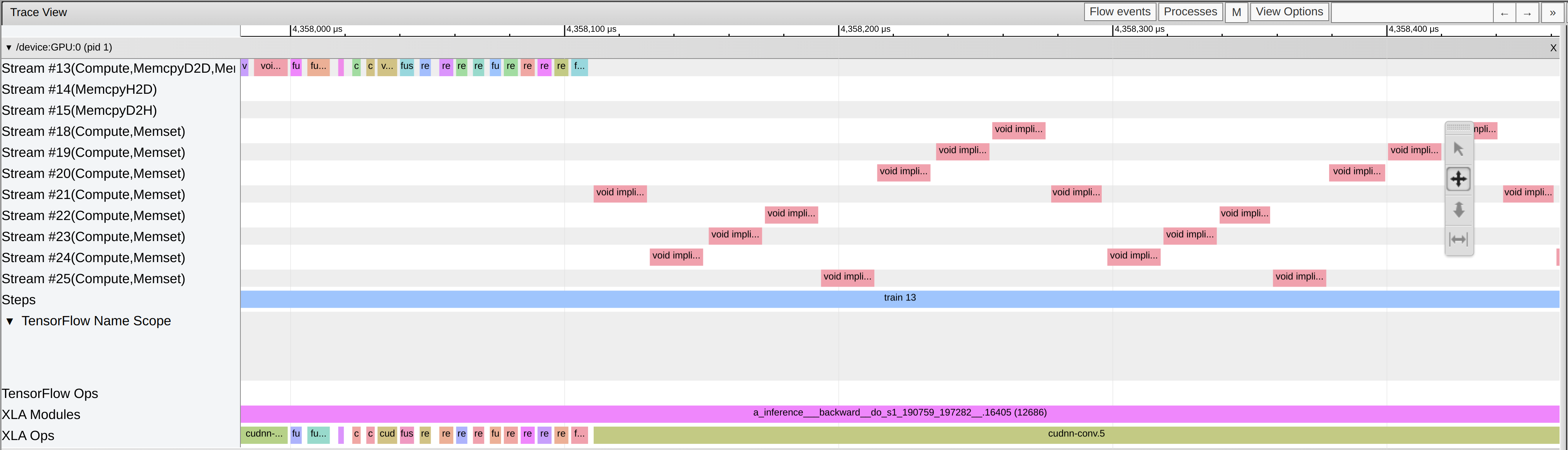
Notice that the sequential implicit conv kernels we were hoping to make parallel belong to the same expensive conv kernel
Misc
Use hotkeys when navigating the trace viewer! Zoom in and out with W and S, and left and right with A and D. It’s much, much quicker that way.
XLA op names on the tensorboard trace viewer: “Gradient Computation for Activations (cuda-conv): Needed to propagate gradients back through the network. Gradient Computation for Weights (cuda-conv-bw-filter): Needed to update the convolutional filter weights based on the loss gradient.” -chatGPT
Questions
- What is
occupancy_min_grid_size? - What is the relationship between batch size and tensorcore eligbility?
References
https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras