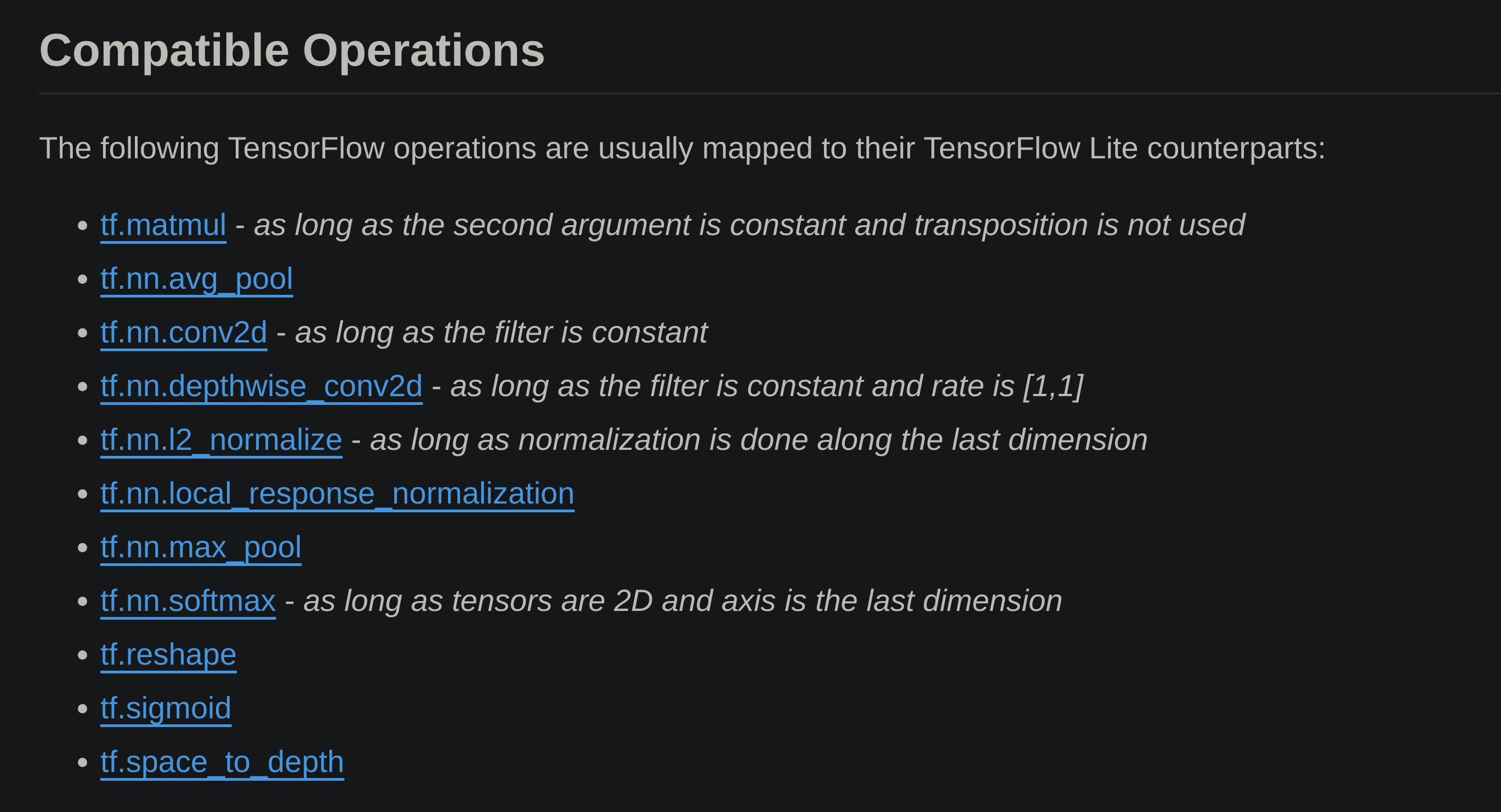
XLA Case Study
Existing Tutorials
-
https://whatdhack.medium.com/tensorflow-graph-graphdef-grappler-xla-mlir-llvm-etc-615191e96ebc
-
https://whatdhack.medium.com/tensorflow-graph-graphdef-grappler-xla-mlir-llvm-etc-615191e96ebc
AnalyticalCostEstimator- based on the hardware, static shape inferenceop_level_cost_estimator- based on the number of different operations and the expected IO (must be taking into account different memory cache speeds)- the timeline in the tf profiler will show the fastest kernel selected, but this is different than the ?tensorflow? kernel?
- “XlaLaunch, _XlaCompile, XlaRun , _XlaMerge, and XlaClusterOutput are the ops that XLA rewrites a Grappler graph with”
Observations
Kernel Stats
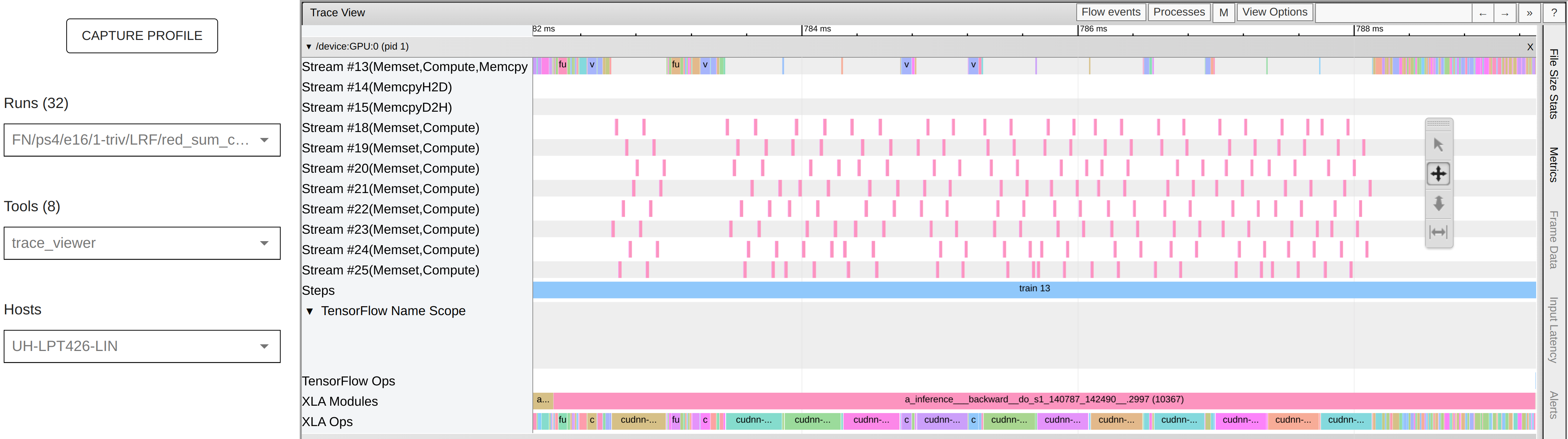
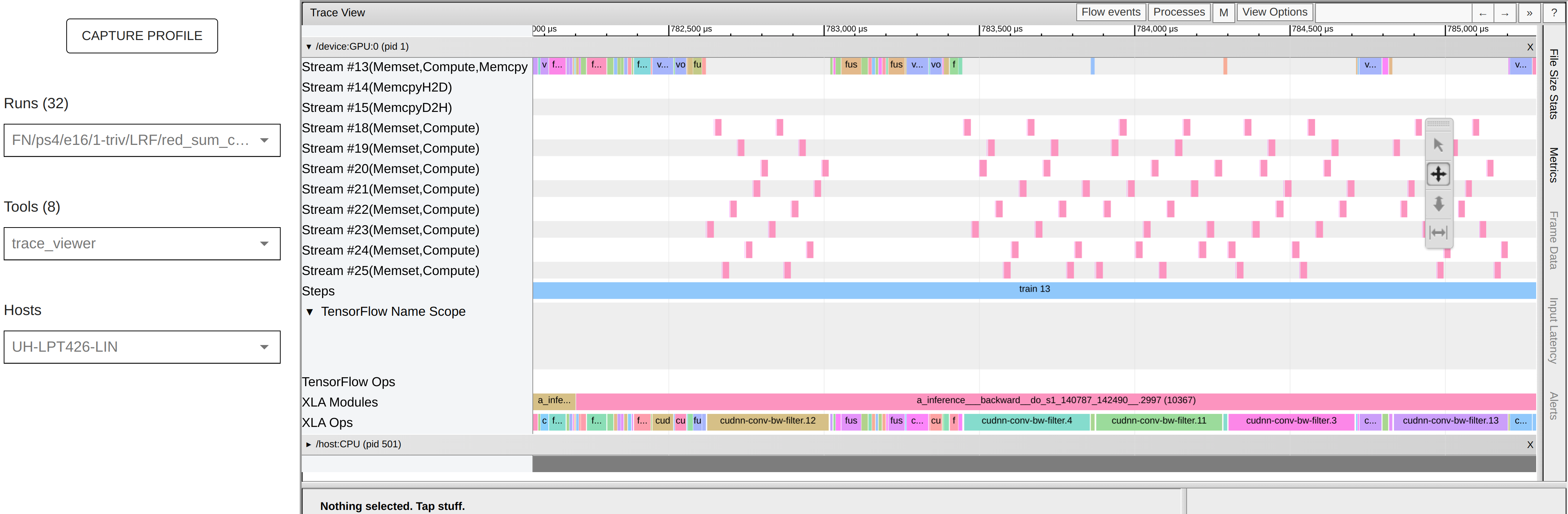
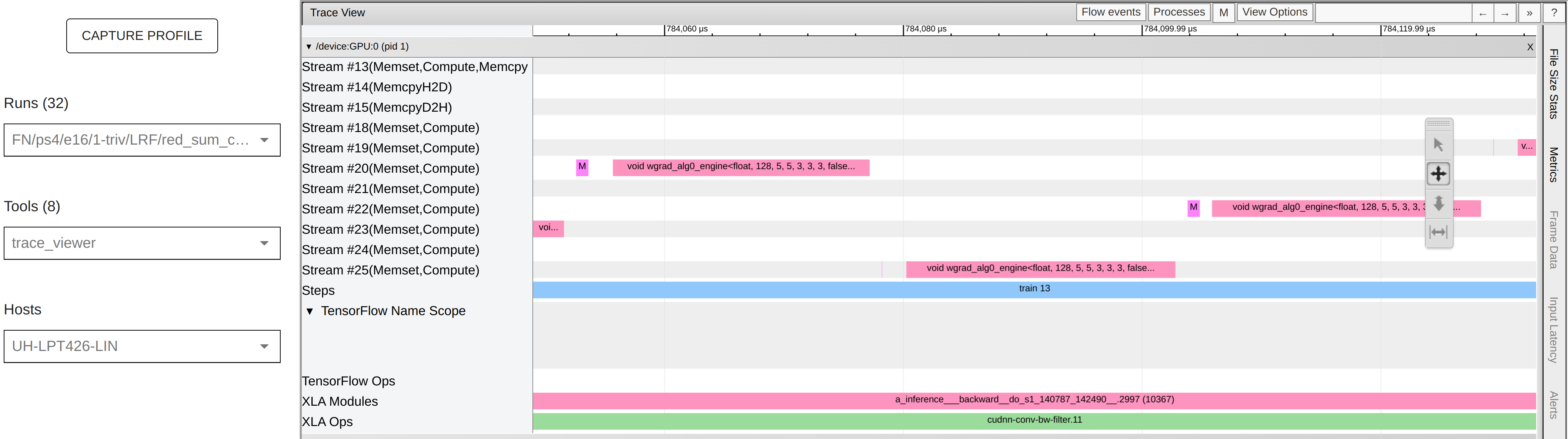
Trace Viewer
Experiments
making the context run in parallel and adding them together
doesn’t actually make anything run in parallel
TODO paste the code
adding tf.function() around BasicLayer call()
Doesn’t let you - something about shape being ill defined, which is strange. . If i just have the tf.function call on the FocalModulation (this part) it still works. But if i try to add it to the BasicLayer on this line it throws an error about the shape being None.
its interesting that 1) the BasicLayer calls FocalModulation. 2) the whole stage 1 is jit compiled and the BasicLayer is inside stage 1, so why is this somehow not able to infer any shapes? is it worth trying to fix this if im not sure its going to give a boost anyway?
adding tf.function() around FocalModulation call()
Makes 0 difference - TODO screenshot the tensorboard profiles
context = tf.function(self.focal_layers[0])(context)
adding tf.function() the specific calls to
TODO screenshot the tensorboard profiles TB/FN/ps4/e16/2262/LRF/tf_func_FL
code changed from
context = self.focal_layers[0](context)
to
context = tf.function(self.focal_layers[0])(context)
change the batch size and look at the kernels used in the trace viewer
removing tensor slicing from the loop when calculating the gates
changing the conv2d with groups=channels to depthwise conv2d explicitly
change mlp ratio from 4 to 1
For inference, we will want to compile long before it’s time to use the model. For that we will use AOT compilation, which requires converting tensorflow ops to TFLite so it can run faster.